프로그래밍 언어/Python
Day_3 다양한 변수 타입
새싹 개발자 뚜비
2022. 1. 27. 21:44
728x90
다양한 변수 타입
'''
python에서 범용적으로 많이 사용하는 dictionary에 대한 수업
[{key : value}, {}] : mapping type
선언 : {key : value}, dict{}
순서 X, 키 중복 X, 수정 O, 삭제 O
'''
# 모든 데이터 값을 value 값으로 넣을 수 있음.
# 가장 일반적인 선언 방법
tmpDict = { \
'name' : 'ddubi',
'phone' : '01012345678',
'birth' : '000000'
}
print('type : ', type(tmpDict), tmpDict)
# in 연산자 : key 유무를 확인하는 용도
print('key 검사 : ', 'name' in tmpDict)
tmpDict = {
'메로나' : [300, 200], # [가격, 수량]
'비비빅' : [400, 200],
'죠스바' : [100, 50]
}
# 메로나의 가격 정보를 확인하고 싶다면?
# 딕셔너리는 데이터에 직접 접근 X, key 값으로 접근 O
print('메로나의 가격은 {}원 입니다.'.format(tmpDict['메로나'][0]))
print('메로나의 수량은 {}개 입니다.'.format(tmpDict['메로나'][1]))
# 새로운 데이터를 추가하고 싶다면?
# 메로나의 값이 [500, 50]으로 변경됨, 딕셔너리는 키를 중복할 수 없어서 키가 변경됨
tmpDict['메로나'] = [500, 50]
print('data : ', tmpDict)
# 메로나의 가격을 10% 인상하고자 한다면?
melonaLst = tmpDict['메로나']
print('melona value : ', type(melonaLst), melonaLst)
melonaLst[0] = melonaLst[0] * 1.1
print('data : ', tmpDict)
tmpDict = {
'Name' : 'ddubi',
'City' : 'Seoul',
'Age' : 7,
'Grade' : 'A+',
'status' : True
}
# 수정
tmpDict['Name'] = '뚜비'
print('data : ', tmpDict)
# 확인
print('print : ', tmpDict['Name'])
print()
# 딕셔너리를 만드는 2번째 방법
tmpDict01 = dict([
('city', 'seoul'), ('age', 7)
])
print('type : ', type(tmpDict01), tmpDict01)
print()
# 딕셔너리를 만드는 3번째 방법
# 키를 함수형으로 선언 '' 나 "" 사용 X
tmpDict02 = dict(
city = 'seoul',
age = 7
)
print('type : ', type(tmpDict02), tmpDict02)
print('key를 이용한 값 출력 : ', tmpDict02['city'])
# 방법_1 (일반적인 방법): key가 존재하지 않으면 오류가 발생
print('key를 이용한 값 출력 : ', tmpDict02.get('age'))
# 방법_2 : key가 존재하지 않으면 None으로 출력하여 데이터를 가져오지 않고 오류를 내지
print()
tmpDict02['name'] = '뚜비' # 일반적인 방법
tmpDict02.update({'name' : 'ddubi'})
print('data : ', tmpDict02)
print()
# zip
# 딕셔너리를 만드는 4번째 방법 : 튜플, 리스트, 튜플&리스트 데이터끼리도 가능
keys = ('apple', 'pear', 'peach')
values = (1000, 1500, 2000)
zipDict = dict(zip(keys, values))
# 딕셔너리 형식으로 바꿔줘야 dict 형식으로 나옴
# 아니면 class가 zip으로 나와서 key와 value 값이 매칭이 안됨
print('type : ', type(zipDict), zipDict)
print()
# dict 형식으로 바꿔주지 않으면 코드가 길어짐 ↓
print('len : ', len(keys), len(values))
zipDict = {}
for idx in range(len(keys)) :
zipDict[keys[idx]] = values[idx]
print('type : ', type(zipDict), zipDict)
print()
# 딕셔너리는 반복이 안됨. 순서가 없기 때문
# 딕셔너리 소유 함수 / 함수를 이용하면 루핑이 가능해짐(반복문 사용 가능)
# keys(), values, items()
for key in zipDict.keys() :
print('{} : {}'.format(key, zipDict.get(key)))
for value in zipDict.values() :
print(value)
for key, value in zipDict.items() :
print('{} : {}'.format(key, value))
# pop
print('pop : ', zipDict.pop('apple'))
print('data : ', zipDict)
print()
zipDict.clear()
print('clear : ', zipDict)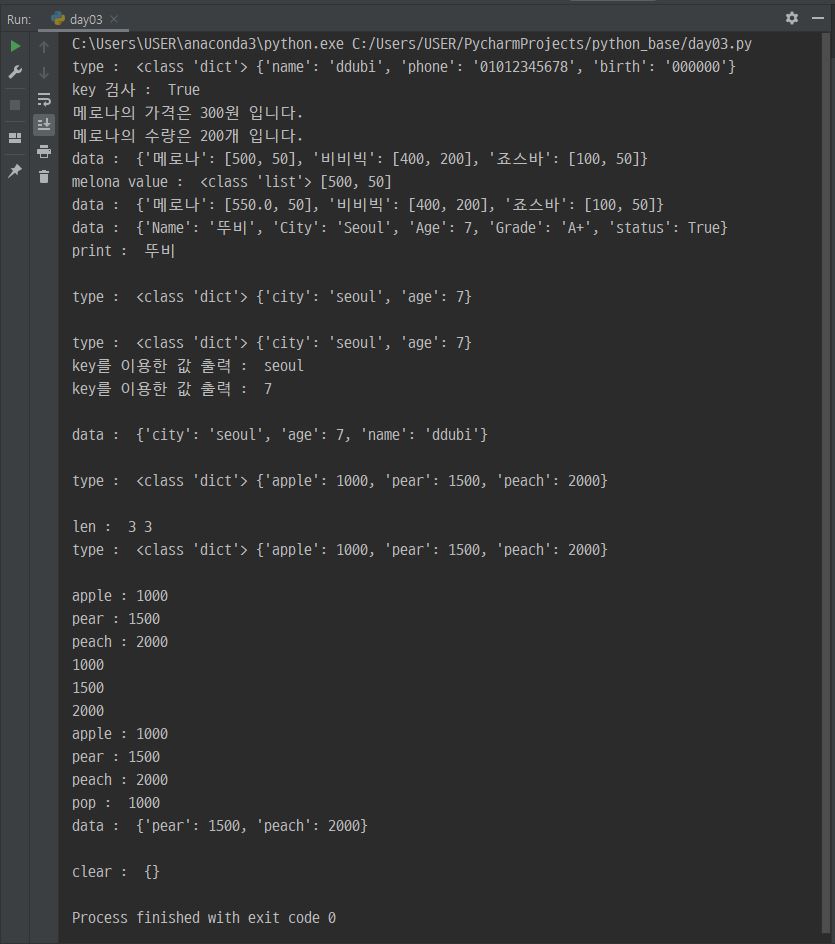
'''
set 집합의 자료형
- 선언 : {}, set()
- 순서 X, 중복 X
- 인덱싱 X, 슬라이싱 X
- 활용의 빈도는 높지 않음
'''
# 중복을 허용하지 않기 때문에 유니크한 값만 확인 가능
#tmpSet = {1,2,3,3,3,3,3,'ddubi'}
tmpSet = set([5,4,1,2,3,3,3,3,3,'ddubi'])
print('type : ', type(tmpSet), tmpSet)
print('dir : ', dir(tmpSet))
# print('indexing : ', tmpSet[0]) -- error
# 이터레이터가 있기 때문에 루핑은 가능하지만
# 순서가 없기 때문에 인덱싱이 되지않음
for s in tmpSet :
print(s)
# set 데이터의 순서가 있고 싶다면 형변환을 통해 사용해야함.
tmpT = tuple(tmpSet)
print('type : ', type(tmpT), tmpT)
tmpL = list(tmpSet)
print('type : ', type(tmpL), tmpL)
# 리스트에서 유니크한 값을 얻고 싶다면?
gender = ['남', '남', '여', '남', '남', '여', '남', '남', '여']
sgender = set(gender)
print('중복 제거 : ', type(sgender), sgender)
set01 = set('ddubi')
print('set01 : ', set01) # 인덱싱해서 하나의 set으로 만듦
set02 = set([1, 2, 3, 4, 5])
set03 = set([3, 4, 5, 6, 7])
print('intersection : ', set02.intersection(set03)) # 교집합
print('union : ', set02.union(set03)) # 합집합
print('difference : ', set02.difference(set03)) # 차집합
set02.add(6) # 하나만 추가 가능
print('add : ', set02)
set02.update([7, 8]) # 리스트 형식으로 여러개 추가 가능
print('update : ', set02)
set02.remove(6)
print('remove : ', set02)
set02.clear()
print('clear : ', set02)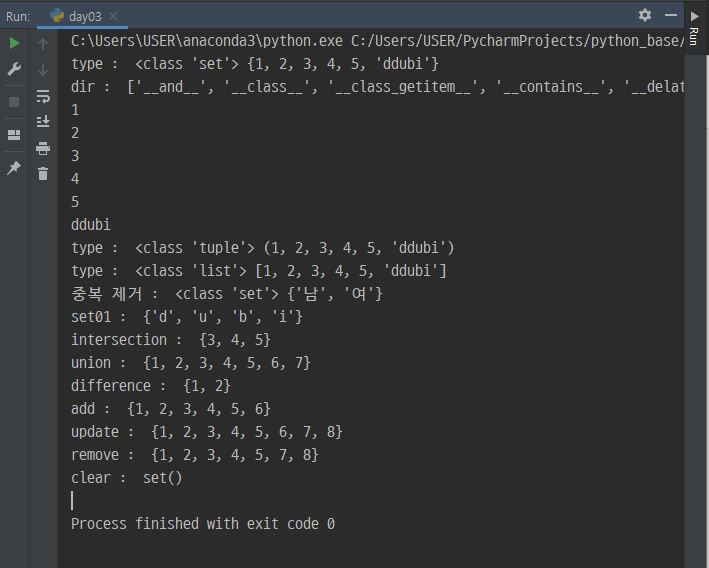
'''
boolean Type
- True | False
- 논리연산자(not, and, or)
- 비교연산자(~ , & , | )
- "", [], (), {}, 0, None -> False
'''
print('boolean : ', bool(0))
print('boolean : ', type([]), bool([]))
trueFlag = True
falseFlag = False
# 논리곱
print()
print('T and T : ', trueFlag & trueFlag)
print('T and F : ', trueFlag & falseFlag)
print('F and T : ', falseFlag and trueFlag)
print('F and F : ', falseFlag and falseFlag)
# 논리합
print()
print('T and T : ', trueFlag | trueFlag)
print('T and F : ', trueFlag | falseFlag)
print('F and T : ', falseFlag or trueFlag)
print('F and F : ', falseFlag or falseFlag)
print()
print('not : ', not trueFlag)
print('int : ', int(falseFlag))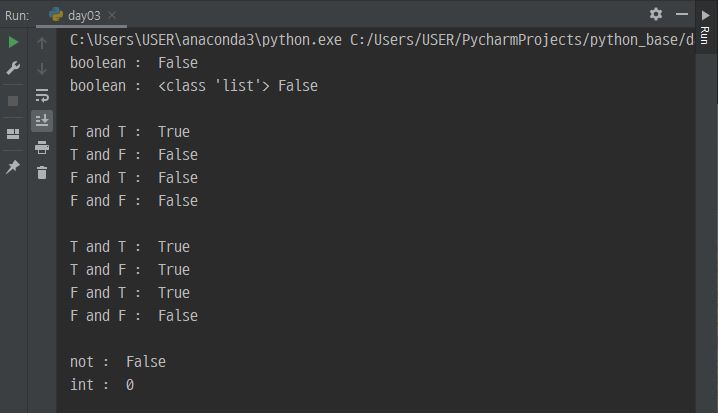
'''
날짜 (파이썬 내장 함수는 아님)
특정패키지의 모듈로 가져와야함
'''
# from 패키지, import 모듈,함수이지만 파이썬 약간 제멋대로임
# timedelta : week, day, hour, minute, second 조작
# relativedelta : year, month 조작
from datetime import date, datetime, timedelta
from dateutil.relativedelta import relativedelta
from dateutil.parser import parse
today = date.today()
print('type : ', type(today), today)
print(today.year, today.month, today.day)
day_time = datetime.today()
print('type : ', type(day_time), day_time)
print(day_time.hour, day_time.minute, day_time.second, day_time.microsecond)
today01 = date.today()
day = timedelta(days=-1)
print('하루 전 날짜 : ', type(day), today01 + day)
today02 = date.today()
day = relativedelta(months=-2)
print('두달 전 날짜 : ', type(day), today02 + day)
myDate = parse("2021-01-27")
print('type : ', type(myDate), myDate)
myDate = datetime(2019, 12, 25)
print('type : ', type(myDate), myDate)
# 날짜 타입을 문자열 포맷으로 지정 할 수 있다. %m %d %y , %H %M %S
# strftime(날짜 -> 문자) / strptime(문자 -> 날짜)
print('format : ', myDate.strftime("%m-%d-%y"))
print('날짜 -> 문자 : ', type(myDate.strftime("%m-%d-%y")), myDate.strftime("%m-%d-%y"))
str = "2019-12-25"
print('문자 -> 날짜 : ', type(datetime.strptime(str, '%Y-%m-%d')))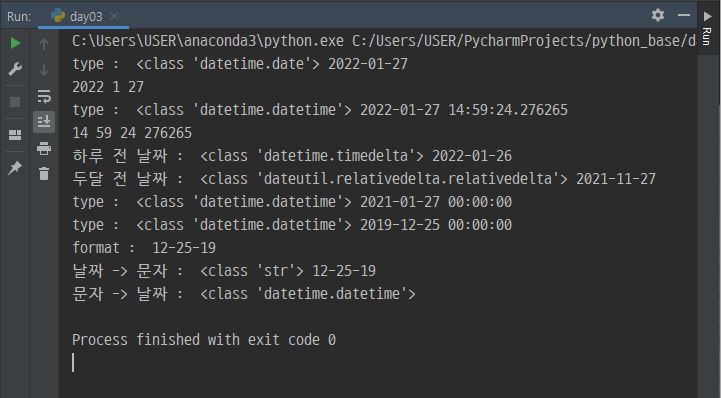
사용자입력
'''
사용자입력
'''
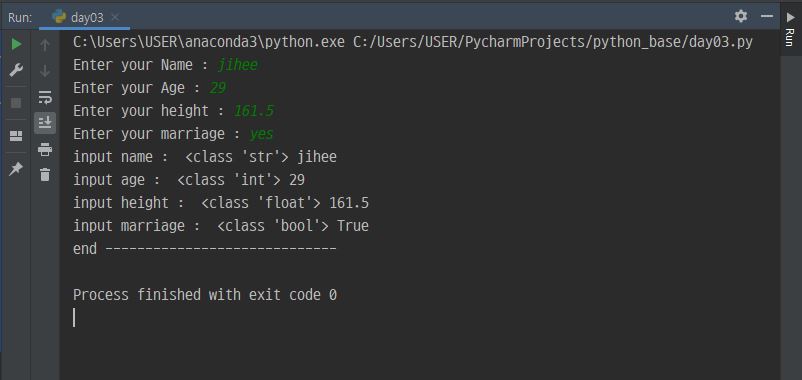
name = input('Enter your Name : ')
age = int(input('Enter your Age : '))
height = float(input('Enter your height : '))
marriage = bool(input('Enter your marriage : '))
# 입력받는 내용과 관계없이 불리언으로 받는건 의미없음
print('input name : ', type(name), name)
print('input age : ', type(age), age)
print('input height : ', type(height), height)
print('input marriage : ', type(marriage), marriage)
print('end ----------------------------- ')
# 단어의 빈도수 구하기
# {'love' : 2, 'word' : 2, 'cat' : 1}
word_vec = ['love', 'word', 'love', 'cat', 'word']
print('len : ', len(word_vec))
for word in word_vec :
print(word)
# case 01
wc = {}
for word in word_vec :
wc[word] = wc.get(word, 0) +1
print('case 01 wc : ', wc)
# case 02
wc = {}
for word in word_vec :
wc[word] = word_vec.count(word)
print('case 02 wc : ', wc)
# case 03
wc = {}
for word in word_vec :
if word in wc :
wc[word] += 1
else :
wc[word] = 1
print('case 03 wc : ', wc)
# case 04 : 지양 해야 할 코드(능동적이지 않음)
wc = dict(
love = word_vec.count('love'),
word = word_vec.count('word'),
cat = word_vec.count('cat')
)
print('case 04 wc : ', wc)
# case 05
# set, zip, list com~ 활용해보기
print('set : ', set(word_vec))
print('comprehension : ', [word_vec.count(i) for i in set(word_vec)])
result = dict(zip(set(word_vec), [word_vec.count(i) for i in set(word_vec)]))
print('case 05 wc : ', result)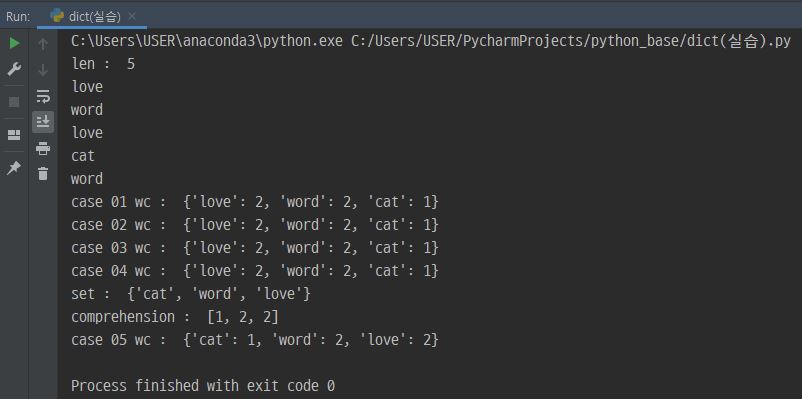
728x90