머신러닝(Machine Learning)을 공부해보자 ! (개념 익히기)
머신러닝 또는 기계학습이란?
위키백과가 말하길 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구이고 인공지능의 한 분야로 간주된다고 하는데 명확히 와닿지는 않는다.
머신러닝에 대한 다양한 표현들이 있지만 나는 데이터를 기반으로 자동으로 규칙을 학습하고 결과를 예측하는 알고리즘 기법이라고 생각한다.
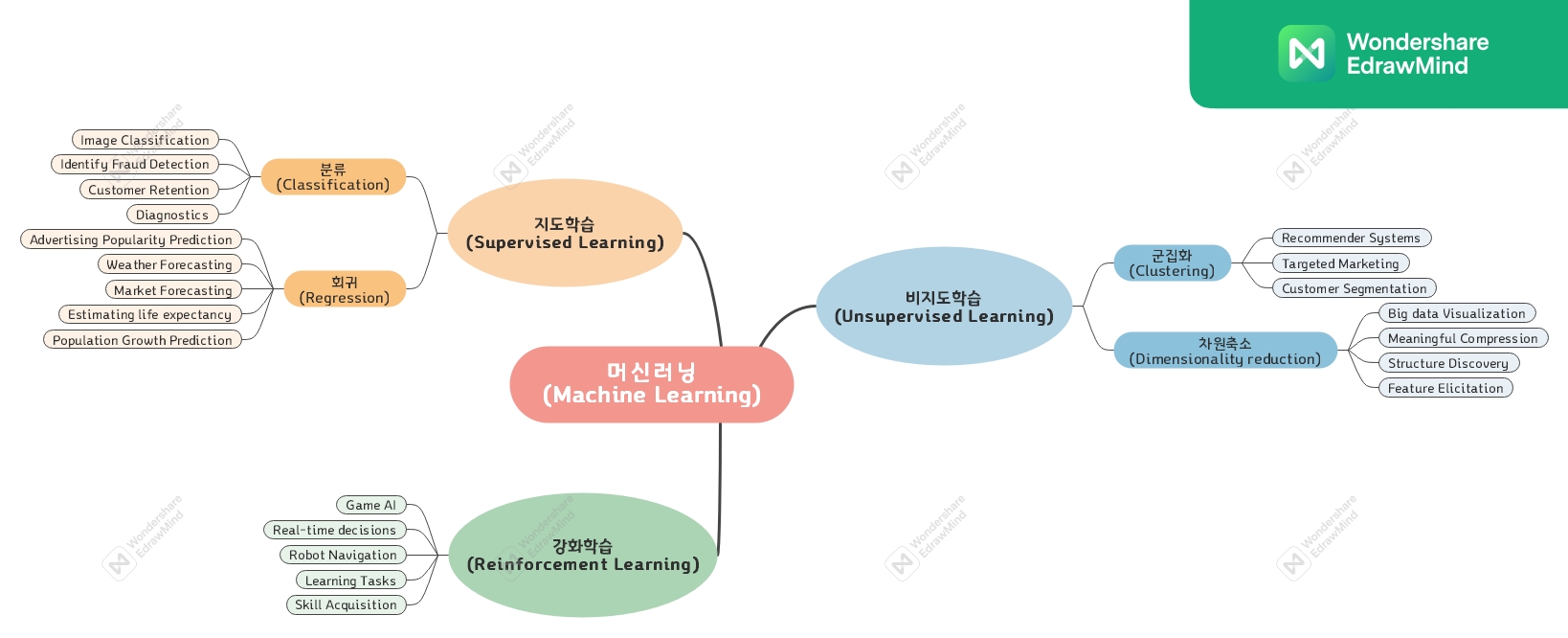
머신러닝의 종류
일반적으로 머신러닝의 학습 방법은 지도학습(Supervised Learning), 비지도학습(Un-Supervised Learning), 강화학습(Reinforcement Learning) 3가지로 나뉜다.
지도학습
지도학습이란 컴퓨터에게 정답(label)이 있는 데이터을 사용하여 학습시키는 것이다.
예를들어 머신에게 과일 사진들(input data)을 주고 이건 사과야, 이건 포도야 라는 정답(label data)을 알려주면서 학습시키는 것이다.
지도학습 훈련은 컴퓨터의 예측값(prediction)과 의도했던 정답(label)이 같아지도록 하는것으로 지도학습의 종류로는 대표적으로 분류(Classification)와 회귀(Regression)가 있다.
분류(Classification)
분류란 주어진 데이터를 정해진 카테고리(라벨)에 따라 분류하는 것으로 이진분류, 다중분류 나누어진다.
- 이진분류
이진분류는 주어진 데이터를 두가지 중 하나로 분류하는 것이다.
대표적인 예로는 스팸 메일을 구분하는 모델이다.
메일(input data)이 스팸메일인지 일반메일인지 분류하는것으로 스팸메일과 일반메일로 구분한다.
코로나 바이러스에 감염된 사람을 양성인지 음성인지 구분하는 것 또한 이진분류라고 볼 수 있다.
- 다중분류
다중분류는 주어진 데이터를 여러개의 값 중 하나로 분류하는 것이다.
예를 들어 이 과일은 무엇일까?라는 질문에 사과, 포도, 오렌지 등 중에 하나로 분류하도록 한다거나 주어진 수능 성적이 몇 등급인지 분류하도록 하는 것이다.
회귀(Regression)
회귀란 어떤 데이터들의 특징(Feature)을 기준으로 값을 예측하는 것으로 어떠한 패턴이나 트렌드, 경향 등을 예측하는데 사용된다. 보통 숫자를 예측하고 싶을 때 회귀를 사용하며 분류와 달리 값이 0과 1같은 하나의 값으로 딱 떨어지는 것이 아니기 때문에 결과값으로는 실수를 가질 수 있고 그 값들은 연속성을 갖는다.
예를 들어 지역, 평수, 아파트라는 특징(Feature)을 가지고 집 값을 예측한다거나 온도에 따른 아이스크림 판매량을 예측하는 것이다.
비지도학습
비지도학습이란 컴퓨터에게 정답(label)이 없는 데이터를 학습시키는 것으로 데이터의 패턴과 유사도를 학습한다.
정답(label)이 없기 때문에 컴퓨터는 유사한 패턴과 속성을 기준으로 데이터를 그룹화 시킨다.
예를들어 비지도 학습으로 과일을 분류한다고 하면
노란색을 기준으로 바나나, 레몬, 망고 등을 한 그룹으로
동그란 모양을 기준으로 오렌지, 멜론, 수박 등을 한 그룹으로
크기를 기준으로 사과, 오렌지, 복숭아 등을 한 그룹으로 분류할 수 있을 것이다.
대표적으로 군집화(Clustering), 연관 규칙 학습(Association rule learning), 차원축소(Dimensionality Reduction) 기술들이 있다.
군집화(Clustering)
군집화란 분류에 대한 기준이 없이 컴퓨터가 스스로 데이터를 학습하여 유사한 속성의 데이터들을 그룹화하는 기술로 관측치를 묶어 그룹핑해준다.
지도학습의 분류와 비슷하지만 군집화는 명확하게 찾는 것이 무엇인지 모르기 때문에 지도학습의 분류와는 다르다.
군집화(Clustering)에 대한 내용은 많기 때문에 군집화를 공부할 때 조금 더 자세히 내용을 정리하려고 한다.
연관 규칙 학습(Association rule learning)
연관 규칙 학습이란 대량의 데이터 간의 흥미로운 관계(relationship) 혹은 패턴(pattern)을 학습하는 기술로 서로 연관된 특징을 묶어 그룹핑 해준다.
일명 장바구니 분석이라고 불리우며 유통 및 마케팅 분야에서 많이 활용되고 있는데 고객의 장바구니에 담긴 물건을 통해 상품을 추천해주는 기술이라고 생각하면 쉽다.
아래의 표를 통해 좀 더 알아보도록 하자.
| 주문번호 | 라면 | 계란 | 식빵 | 우유 | 햄 |
| 1 | O | O | X | X | O |
| 2 | O | O | X | X | X |
| 3 | O | O | X | X | X |
| 4 | X | X | O | O | X |
(유튜브 '생활코딩' [연관규칙학습] 강의 인용)
이 표를 보면 라면과 계란은 연관성이 높은것을 알수있다.
이처럼 데이터(상품)간의 연관성을 파악할 수 있다면 구입할 가능성이 높은 상품을 추천해주어 더 많은 이익을 창출할 수 있다.
연관 규칙 학습 모델은 이미 우리 삶에서도 많이 찾아볼 수 있다.
영화 추천, 쇼핑 추천, 동영상 추천 등 유튜브, 넷플릭스, 쿠팡 등 많은 곳에서 활용되고 있는 것을 알수있다.
(예전에는 추천이라는 단어가 들어간 기능은 전부 이 학습 모델을 사용했지만 최근엔 다양한 방법들을 이용해 성능을 높이고 있다고 한다.)
차원축소(Dimensionality reduction)
차원축소는 높은 차원의 데이터 학습을 더 효율적이게 하기 위해 사용되는 기술로 복잡한 데이터들을 2차원 시각화를 시키거나 변수 사이의 공통적인 정보만 남겨 점수화 시키거나 차원을 줄여 차원의 저주를 피하고 지도학습의 성능을 높이기 위해 사용한다.
전통적인 통계에서 차원 축소의 대표적인 방법은 주성분 분석(PCA : Principal Component Analysis)이 있다.
강화학습
(추후 내용 추가)